My first professional work as a software developer was writing Clipper code. Clipper was a compiler for dBASE code with object-oriented extensions. This was in the days of DOS, and the entire application was written in a single language. We didn't even use SQL. Instead, the data storage was shared DBF files on a new concept, the LAN (I remember reading a PC-Magazine of that era declaring that the current year was the "Year of the LAN").
We are entering a new era of software development. For most of our (short) history, we've primarily written code in a single language. Of course, there are exceptions: most applications now are written with both a general purpose language and SQL. Now, increasingly, we're expanding our horizons. More and more, applications are written with Ajax frameworks (i.e., JavaScript). If you consider the embedded languages we use, it's even broader: XML is used as an embedded configuration language widely in both the Java and .NET worlds.
But I'm beginning to see a time where even the core language (the one that gets translated to byte code) will cease its monoculture. Pretty much any computer you buy has multiple processors in it, so we're going to have to get better writing threading code. Yet, as anyone who has read Java Concurrency in Practice by Brian Goetz (an exceptional book, by the way), writing good multi-threading code is hard. Very hard. So why bother? Why not use a language that handles multiple threads more gracefully? Like a functional language? Functional languages eliminate side effects on variables, making it easier to write thread-safe code. Haskell is such a language, and implementations exist for both Java (Jaskell) and .NET (Haskell.net). Need a nice web-based user interface? Why not use Ruby on Rails via JRuby (which now support RoR).
Applications of the future will take advantage of the polyglot nature of the language world. We have 2 primary platforms for "enterprise" development: .NET and Java. There are now lots of languages that target those platforms. We should embrace this idea. While it will make some chores more difficult (like debugging), it makes others trivially easy (or at least easier). It's all about choosing the right tool for the job and leveraging it correctly. Pervasive testing helps the debugging problem (adamant test-driven development folks spend much less time in the debugger). SQL, Ajax, and XML are just the beginning. Increasingly, as I've written before, we're going to start adding domain specific languages. The times of writing an application in a single general purpose language is over. Polyglot programming is a subject I'm going to speak about a lot next year. Stay tuned...
Tuesday, December 05, 2006
Friday, November 17, 2006
Enforcing Good Bahavior
I hate tools that force you down a particular path, and fight you all the way if you want to do something different than what they want. Every development environment and framework has their own path of least resistance, and various punishments for those that wander from the path. For example, Visual Studio encourages poorly designed applications by making it trivially easy to drop database components onto a web page, wire everything on that page via properties, and just click run. No real-world application should be written like that: it is a maintenance nightmare. Of course, you can write well structured applications in .NET (we do it all the time), but you have to do it around some of the designers and other affordances.
I really like tools that encourage good behavior and punish bad behavior. For example, Subversion is almost perfect for Agile projects because it strongly encourages you to check in early and often. Because it doesn't do any file locking, any file upon which you are working is subject to change by another developer. If you wait too long to check in, you are punished with Merge Hell, where you have to reconcile the differences between the changed file. The easiest way to avoid Merge Hell is to check in very frequently. Statistically, you are much less likely to bump into Merge conflicts.
A framework that encourages good behavior is Ruby on Rails. It builds layered applications by default. In fact, you would have to fight Rails hard to build a highly coupled application. Similarly, if you don't write good unit and functional tests in Rails, you are in great danger of building a very fragile application.
Both Subversion and RoR have the right priorities: reward the Right Thing and punish the Wrong Thing.
I really like tools that encourage good behavior and punish bad behavior. For example, Subversion is almost perfect for Agile projects because it strongly encourages you to check in early and often. Because it doesn't do any file locking, any file upon which you are working is subject to change by another developer. If you wait too long to check in, you are punished with Merge Hell, where you have to reconcile the differences between the changed file. The easiest way to avoid Merge Hell is to check in very frequently. Statistically, you are much less likely to bump into Merge conflicts.
A framework that encourages good behavior is Ruby on Rails. It builds layered applications by default. In fact, you would have to fight Rails hard to build a highly coupled application. Similarly, if you don't write good unit and functional tests in Rails, you are in great danger of building a very fragile application.
Both Subversion and RoR have the right priorities: reward the Right Thing and punish the Wrong Thing.
Thursday, November 02, 2006
Entropic Software
I've reached a bit of an epiphany lately about software and complexity. "Epiphany" is probably too strong a word because it implies a sudden revelation. My thoughts about software complexity have more crept up than hit me over the head. But no matter how it got here, I'm convinced that software breeds entropy. And I have examples.
If you look at information theory (the mathematics behind information itself, not "information technology", like electronics), you might be startled to discover that the definition of "entropy" and "information" are essentially the same. Both measure the relative complexity of systems. Here's an example. Compare a class of water to a class filled with the makings of a mud pie. Which has more information? Clearly, the mud pie glass does because it is much more difficult to describe exactly. Water is easy: "A glass full of water". But a glass full of mud pie material is much more difficult. You have dirt, which is itself rich in information (composition, density, etc), plus rocks and twigs (what type of rocks, twigs, etc). From an information standpoint, the glass of mud pie is has much more information. The same is true of entropy. More entropic systems have more information density than less entropic ones. If you think of "entropy" as the movement from structure to chaos, you can see that chaotic systems have more information, just as the mud-pie glass has more information. The information density of highly entropic systems is greater than of structured, less chaotic systems.
Given all that, let's talk about software. I've come to the conclusion that software wants to be complex. In other words, it tends towards entropy unless someone takes active measures to stop it. I see examples of this every day, both building and using software. Software wants, needs, strives to be complicated. I don't know if it's something inherent in having an ultimately flexible palate upon which to build things (i.e., general purpose programming languages), something about the nature of engineering, or something about the people who really want to build software. Whatever causes this tendency, it must be assiduously fought at every turn.
Here's a concrete example from the recent past. During the design of Unix, lots of smart guys had observed this tendency towards complexity and fought it down diligently. To design the commands of the operating system, they decided to make everything as simple as they could, and establish simple rules about how different utilities talked to one another: everyone consumes plain text, and everyone produces plain text. While simple, this is a very effective way to create modular little programs that play nicely with a whole host of other simple programs. The utility of this simple idea has spawned many useful applications (by combining simple parts) beyond what the designers anticipated. Another example of the value of simplicity is the HTTP protocol. So simple you can understand it in an afternoon, yet sophisticated enough to create the largest distributed environment in the universe (as far as we know), the Internet.
Here's a counter example. When designing Office and Windows, Microsoft bumped into the same problem: we need to all applications to talk to one another. Recreating the simple mechanism of Unix didn't seem enough: applications in Windows were event driven, graphical, multi-threaded beasts that couldn't be bothered with simple command lines. Thus, DDE was born (Dynamic Data Exchange). DDE was a way for one binary hairball to talk to another binary hairball. Thus, Word and Excel could send information back and forth. But, as it turns out, DDE was fragile. Both applications had to be running, and in the correct mode to be able to talk to one another. DDE was all about sending information, not driving the other application. And thus is was considered not robust enough. So, let's add more complexity. OLE was born (Object Linking and Embedding). This allowed 2 things: embed an application inside another one, so that the user could interact with the spreadsheet embedded in a Word document. This, by the way, is why Office document formats are so obtuse. Each of the Office documents must act as a container for any other OLE object that might be embedded. The other feature of OLE was the ability for one application to drive another through background commands. This aspect of OLE was split off and became COM (and, its distributed cousin, DCOM). That wasn't sufficient for a variety of reasons, so we got COM+. Then .NET Remoting. Which leads us back around to Monad (or whatever Microsoft is calling it now that it's official - Windows Power Shell). Monad is a way for...wait for it...a command line script (or batch file) to make two application interact with one another, through COM+ interfaces. The idea is that you can pump some rows from an Excel spreadsheet into Outlook as email addresses and tell Outlook to send some files to the recipients.
But what is the problem we're trying to solve? Getting applications to talk to one another. I could do the same thing in Unix, with several of its tools, without all the intervening complexity. Building small modular parts with clean interfaces (the Unix way) means that I get to pick and choose what combinations I want. Using the Monad way, the designers of the binary hairballs that I need to get to talk must have anticipated what I want to do before I can use their hairball to do it. In other words, you cannot use Monad in a way unsupported by the huge binary behemoths for which it facilitates communication between.
This is a good example of the way software has of becoming highly entropic. The problem is that I need to have 2 applications send information back and forth. The simple way is the Unix way. The entropic, highly complex, fragile, limited way is to build great complex edifices, with lots of opaque moving parts. If we're ever going to produce really great software, we have to avoid entropic software like the plague that it is.
If you look at information theory (the mathematics behind information itself, not "information technology", like electronics), you might be startled to discover that the definition of "entropy" and "information" are essentially the same. Both measure the relative complexity of systems. Here's an example. Compare a class of water to a class filled with the makings of a mud pie. Which has more information? Clearly, the mud pie glass does because it is much more difficult to describe exactly. Water is easy: "A glass full of water". But a glass full of mud pie material is much more difficult. You have dirt, which is itself rich in information (composition, density, etc), plus rocks and twigs (what type of rocks, twigs, etc). From an information standpoint, the glass of mud pie is has much more information. The same is true of entropy. More entropic systems have more information density than less entropic ones. If you think of "entropy" as the movement from structure to chaos, you can see that chaotic systems have more information, just as the mud-pie glass has more information. The information density of highly entropic systems is greater than of structured, less chaotic systems.
Given all that, let's talk about software. I've come to the conclusion that software wants to be complex. In other words, it tends towards entropy unless someone takes active measures to stop it. I see examples of this every day, both building and using software. Software wants, needs, strives to be complicated. I don't know if it's something inherent in having an ultimately flexible palate upon which to build things (i.e., general purpose programming languages), something about the nature of engineering, or something about the people who really want to build software. Whatever causes this tendency, it must be assiduously fought at every turn.
Here's a concrete example from the recent past. During the design of Unix, lots of smart guys had observed this tendency towards complexity and fought it down diligently. To design the commands of the operating system, they decided to make everything as simple as they could, and establish simple rules about how different utilities talked to one another: everyone consumes plain text, and everyone produces plain text. While simple, this is a very effective way to create modular little programs that play nicely with a whole host of other simple programs. The utility of this simple idea has spawned many useful applications (by combining simple parts) beyond what the designers anticipated. Another example of the value of simplicity is the HTTP protocol. So simple you can understand it in an afternoon, yet sophisticated enough to create the largest distributed environment in the universe (as far as we know), the Internet.
Here's a counter example. When designing Office and Windows, Microsoft bumped into the same problem: we need to all applications to talk to one another. Recreating the simple mechanism of Unix didn't seem enough: applications in Windows were event driven, graphical, multi-threaded beasts that couldn't be bothered with simple command lines. Thus, DDE was born (Dynamic Data Exchange). DDE was a way for one binary hairball to talk to another binary hairball. Thus, Word and Excel could send information back and forth. But, as it turns out, DDE was fragile. Both applications had to be running, and in the correct mode to be able to talk to one another. DDE was all about sending information, not driving the other application. And thus is was considered not robust enough. So, let's add more complexity. OLE was born (Object Linking and Embedding). This allowed 2 things: embed an application inside another one, so that the user could interact with the spreadsheet embedded in a Word document. This, by the way, is why Office document formats are so obtuse. Each of the Office documents must act as a container for any other OLE object that might be embedded. The other feature of OLE was the ability for one application to drive another through background commands. This aspect of OLE was split off and became COM (and, its distributed cousin, DCOM). That wasn't sufficient for a variety of reasons, so we got COM+. Then .NET Remoting. Which leads us back around to Monad (or whatever Microsoft is calling it now that it's official - Windows Power Shell). Monad is a way for...wait for it...a command line script (or batch file) to make two application interact with one another, through COM+ interfaces. The idea is that you can pump some rows from an Excel spreadsheet into Outlook as email addresses and tell Outlook to send some files to the recipients.
But what is the problem we're trying to solve? Getting applications to talk to one another. I could do the same thing in Unix, with several of its tools, without all the intervening complexity. Building small modular parts with clean interfaces (the Unix way) means that I get to pick and choose what combinations I want. Using the Monad way, the designers of the binary hairballs that I need to get to talk must have anticipated what I want to do before I can use their hairball to do it. In other words, you cannot use Monad in a way unsupported by the huge binary behemoths for which it facilitates communication between.
This is a good example of the way software has of becoming highly entropic. The problem is that I need to have 2 applications send information back and forth. The simple way is the Unix way. The entropic, highly complex, fragile, limited way is to build great complex edifices, with lots of opaque moving parts. If we're ever going to produce really great software, we have to avoid entropic software like the plague that it is.
Monday, October 30, 2006
Post Windows
Professionally, a lot has changed for me over the last few of weeks. I've rolled off the rich client, .NET 2 project to which I've been attached since December and rolled onto a Ruby on Rails project. The projects could hardly be more dissimilar: large (15+ developers, distributed agile desktop application vs. 4 developer, Ruby on Rails project). Add another significant change: I'm now (for the time being, at least), post-Windows. I upgraded my Mac in July to a MacBook Pro, and have been doing .NET development on it using Parallels (which, BTW, works great). On my new project, though, I'm fully Mac: the pairing workstations are Mac Mini's, with 2 keyboards, mice, and monitors. And I've just completed porting all my Java and Ruby conference talks over to the Mac.
This is a big deal for me. For my entire professional life, I've been living with a Microsoft operating system on a daily basis. Starting in DOS 5 back in 1993, then moving to Windows (I've been a power user in all these versions - 3.1, 3.11, 95, NT 4, 2000, XP). Now, though, I'm conducting both my personal and professional lives in OS X. And I'm giddy with joy. I only occasionally need to dip into Windows for 1 of the 2 applications for which I don't have a superior Mac replacement.
Dealing with low-level frustration and annoyance takes a measurable toll on your psyche. I'm not one to be overly religious about tools; I try to learn to use them to their utmost. However, I absolutely believe that my quality of life is better now, in small but subtle ways, mostly having to do with elegance and design. These "OS X rocks, Windows sucks ass" kind of blog entries are generally short on substance, just an inarticulate expression of the intangible. Well, here are some concrete examples.
Windows machines have 2 ways to connect to networks, wired and wireless. On my Dell Latitude 610, when a wireless network is near, it pops up a Windows task tray balloon notifying you that it would like to connect. Yet, when you connect to a wired network, you no longer have a need for the wireless one. Windows still pops up the annoying little balloon, about every 15 seconds, offering to connect you to a network you don't need. When you connect OS X to a wired network, it stops asking you about connecting to a wireless network because it figures out, correctly, that your networking needs are now met.
Another example: power users like to be able to get to the underbelly of all the GUI eye candy to get real work done. I would like access to the Excel command line, in the vain hope that I might be able to open multiple spreadsheets at a time. Yet, in their infinite wisdom, Microsoft has wired Windows to treat Office shortcuts differently, preventing you from getting to the underlying startup command. If you don't believe me, check out this screen shot or check for yourself.

I've done what all power users of Windows ends up doing: I wrote a Ruby script that uses COM automation to open multiple spreadsheets. In fact, my toolbox is full of little scripts and such that get around annoying Windows behavior. Actually, I should be grateful to Microsoft for their annoyances: much of the Productive Programmer book features ways to make programmers more productive in that environment.
Before I get a whole bunch of Spolsky-esque comments about why Windows is the way it is, let me state that I already understand. I know that it's terribly difficult to write an OS that handles all the wide-world of devices that Windows must support because it runs on so much hardware. And, I know that one of Apple's big advantages is their tight coupling of hardware and software. I don't believe that Microsoft is evil or incompetent, and I in fact like some of what they create: .NET has some really nice, elegant parts (and some warts too, like all technologies). But, at the end of the day, as a user of the OS, the little things matter to me. If you cast aside history for the moment, using OS X is much more pleasant and refreshing, regardless of the reasons that got us here.
This is a big deal for me. For my entire professional life, I've been living with a Microsoft operating system on a daily basis. Starting in DOS 5 back in 1993, then moving to Windows (I've been a power user in all these versions - 3.1, 3.11, 95, NT 4, 2000, XP). Now, though, I'm conducting both my personal and professional lives in OS X. And I'm giddy with joy. I only occasionally need to dip into Windows for 1 of the 2 applications for which I don't have a superior Mac replacement.
Dealing with low-level frustration and annoyance takes a measurable toll on your psyche. I'm not one to be overly religious about tools; I try to learn to use them to their utmost. However, I absolutely believe that my quality of life is better now, in small but subtle ways, mostly having to do with elegance and design. These "OS X rocks, Windows sucks ass" kind of blog entries are generally short on substance, just an inarticulate expression of the intangible. Well, here are some concrete examples.
Windows machines have 2 ways to connect to networks, wired and wireless. On my Dell Latitude 610, when a wireless network is near, it pops up a Windows task tray balloon notifying you that it would like to connect. Yet, when you connect to a wired network, you no longer have a need for the wireless one. Windows still pops up the annoying little balloon, about every 15 seconds, offering to connect you to a network you don't need. When you connect OS X to a wired network, it stops asking you about connecting to a wireless network because it figures out, correctly, that your networking needs are now met.
Another example: power users like to be able to get to the underbelly of all the GUI eye candy to get real work done. I would like access to the Excel command line, in the vain hope that I might be able to open multiple spreadsheets at a time. Yet, in their infinite wisdom, Microsoft has wired Windows to treat Office shortcuts differently, preventing you from getting to the underlying startup command. If you don't believe me, check out this screen shot or check for yourself.
I've done what all power users of Windows ends up doing: I wrote a Ruby script that uses COM automation to open multiple spreadsheets. In fact, my toolbox is full of little scripts and such that get around annoying Windows behavior. Actually, I should be grateful to Microsoft for their annoyances: much of the Productive Programmer book features ways to make programmers more productive in that environment.
Before I get a whole bunch of Spolsky-esque comments about why Windows is the way it is, let me state that I already understand. I know that it's terribly difficult to write an OS that handles all the wide-world of devices that Windows must support because it runs on so much hardware. And, I know that one of Apple's big advantages is their tight coupling of hardware and software. I don't believe that Microsoft is evil or incompetent, and I in fact like some of what they create: .NET has some really nice, elegant parts (and some warts too, like all technologies). But, at the end of the day, as a user of the OS, the little things matter to me. If you cast aside history for the moment, using OS X is much more pleasant and refreshing, regardless of the reasons that got us here.
Friday, October 27, 2006
Technology Snake Oil Part 10: Check-box Parity
A pervasive bit of Snake Oil that's been around a long time is Checkbox Parity. This is the requirement by software companies to add features (or make features up) so that they can create the matrix on the side of the box, showing how their version stands up against the competition via columns of checkboxes. The importance of this marketing scheme should not be underestimated. There is a famous essay I read in a treeware book a long time ago by someone whose name I can't remember (but I remember that it was someone notable as a writer). The essay discussed the writer's trials and tribulations with the first versions of Microsoft Word. To compete against WordPefect (the huge market leader at the time), the first version of Word for Windows needed Checkbox Parity with outlining. The author discusses trying to get this to work in Word (it was after all listed at a feature of the product) and continually being frustrated. Finally, after numerous calls to technical support, he finally got the admission that the feature flat out doesn't work, they knew it didn't work, but they had to include it as a feature to achieve Checkbox Parity. This is not a minor point: part of the reason that Word came to dominate WordPerfect in the market place depended on them appearing essentially equavalent in the nascent days of Word. More honest companies (like Ami) failed in the Darwinian environment for word processors that existed before Office crushed all competitors.
This Checkbox Parity also drove the intense competition in the early days of Java IDEs. JBuilder, in its heyday, released a new version every 8 months (which was disastrous for those of us who wrote books about it). This worked well for Borland, who had a very agile development team for JBuilder. It was disastrous for Visual Cafe, who wasn't so agile. For many managers (and, unfortunately, many technologists who know better), the dreaded checkbox matrix on the side of the box determines purchase. Forget well designed, elegant functionality. If you can hack together something that you can reasonably compare to an elegant solution, you can achieve Checkbox Parity.
This same Checkbox Parity will be used to bludgeon Ruby in the marketplace until Ruby achieves the same types of functionality that Java and .NET already have. The CCYAO of large companies will reject Ruby because it doesn't achieve Checkbox Parity with older technologies, regardless of its suitability for a particular development project. If you are trying to sell Ruby in the enterprise, you need a strong antidote to Checkbox Parity Snake Oil.
This Checkbox Parity also drove the intense competition in the early days of Java IDEs. JBuilder, in its heyday, released a new version every 8 months (which was disastrous for those of us who wrote books about it). This worked well for Borland, who had a very agile development team for JBuilder. It was disastrous for Visual Cafe, who wasn't so agile. For many managers (and, unfortunately, many technologists who know better), the dreaded checkbox matrix on the side of the box determines purchase. Forget well designed, elegant functionality. If you can hack together something that you can reasonably compare to an elegant solution, you can achieve Checkbox Parity.
This same Checkbox Parity will be used to bludgeon Ruby in the marketplace until Ruby achieves the same types of functionality that Java and .NET already have. The CCYAO of large companies will reject Ruby because it doesn't achieve Checkbox Parity with older technologies, regardless of its suitability for a particular development project. If you are trying to sell Ruby in the enterprise, you need a strong antidote to Checkbox Parity Snake Oil.
Monday, October 16, 2006
Technology Snake Oil Part 9: The CCYAO
There is a corporate title that no one talks about but who is critical in many organizations: the Chief Cover-Your-Ass Officer. He's the C-level executive to whom you must to sell technology choices. He's always skeptical of new technologies because that's his job.
Back in the days when client/server was the norm and PowerBuilder reigned as king of corporate development, the company for which I worked was promoting Delphi as a good alternative for a particular application for a trucking company. Anyone with any technical knowledge could see quickly that Delphi was a better choice. All the technical people at this company clearly acknowledged that they wanted Delphi, and that a PowerBuilder solution for this particular application was doomed to failure. After a series of meetings with the CCYAO officer and others, they told us their choice: PowerBuilder. When asked why: "There is a good chance that this project will not succeed, and frankly we think the only chance it will succeed is is we use Delphi and your solution. However, if it fails, none of us will be fired if we pick the standard that everyone else uses, PowerBuilder. So, we're going with PowerBuilder. Thanks for coming in."
This is the same C-level executive that coined the phrase "No one ever gets fired for choosing IBM", which has been upgraded to "No one ever gets fired for picking Microsoft". No matter what the technical merits of your solution, ultimately, you've got to sell it to the CCYAO officer.
Back in the days when client/server was the norm and PowerBuilder reigned as king of corporate development, the company for which I worked was promoting Delphi as a good alternative for a particular application for a trucking company. Anyone with any technical knowledge could see quickly that Delphi was a better choice. All the technical people at this company clearly acknowledged that they wanted Delphi, and that a PowerBuilder solution for this particular application was doomed to failure. After a series of meetings with the CCYAO officer and others, they told us their choice: PowerBuilder. When asked why: "There is a good chance that this project will not succeed, and frankly we think the only chance it will succeed is is we use Delphi and your solution. However, if it fails, none of us will be fired if we pick the standard that everyone else uses, PowerBuilder. So, we're going with PowerBuilder. Thanks for coming in."
This is the same C-level executive that coined the phrase "No one ever gets fired for choosing IBM", which has been upgraded to "No one ever gets fired for picking Microsoft". No matter what the technical merits of your solution, ultimately, you've got to sell it to the CCYAO officer.
Tuesday, October 10, 2006
The Condiment Conference Redux
Back in May, I spoke at the first AJAX Experience, and it was a blast. It has been years since I've been to a conference with so much enthusiasm. It is unusual for a conference to focus on what I called a "condiment" technology. You can't write a web application in just Ajax (although TiddlyWiki may prove me wrong on that). Generally, you write the web application in Java, .NET, Ruby, PHP, Python, Perl, or some other "main course" technology. Ajax provides the icing, both visually and via usability polish. Most conferences focus on main courses, but The Ajax Experience focuses on the icing.
This means that this conference has an eclectic mix of developers. Hallway conversations lack the implicit assumptions you can generally make at main course conferences. For example, all Java developers have an implicit context. At The Ajax Experience, you have to throw away your base assumptions, both in sessions and conversations. Just like travel broadens you because you meet people with different contexts and experiences, attending the Ajax Experience does the same for technologists. Instead of the usual low-level animosity that each technology tribe exhibits for the non-tribe members, everyone focuses on common ground. It happens again in October, in Boston. You owe it to yourself to be an ex-patriot for your main course technology and come to the United Nations of web development, The Ajax Experience.
This means that this conference has an eclectic mix of developers. Hallway conversations lack the implicit assumptions you can generally make at main course conferences. For example, all Java developers have an implicit context. At The Ajax Experience, you have to throw away your base assumptions, both in sessions and conversations. Just like travel broadens you because you meet people with different contexts and experiences, attending the Ajax Experience does the same for technologists. Instead of the usual low-level animosity that each technology tribe exhibits for the non-tribe members, everyone focuses on common ground. It happens again in October, in Boston. You owe it to yourself to be an ex-patriot for your main course technology and come to the United Nations of web development, The Ajax Experience.
Saturday, September 30, 2006
EKON 10
I just completed speaking at my 8th Entwickler Konferenz in Frankfurt (I missed the first two, so this one was EKON 10). Speaking at international conferences is enlightening because you quickly learn that the concerns and priorities of US developers don't apply all over the world. For example, I started speaking about Java at this conference back in 1999. At the time, the most popular tool was Delphi and I couldn't get the time of day from most developers when talking about Java. Germany IT is traditionally very conservative and Java was still an upstart platform. By 2001, Java became the safe choice and suddenly there was not 1 but 2 full conferences devoted to it (JAX and WJAX) that drew bigger crowds than Entwickler (which, by the way, is German for "Developer"). This year, I'm talking to everyone about Ruby on Rails in the hallways and no one has heard of it. That'll change in February, when I'm proposing a RoR talk at the Webinale Konferenz.
An interesting thing happened at breakfast this morning that highlights why I like this conference so much. Terry (my colleague from Atlanta) and I planned to meet another speaker from Amsterdam who we've known for years for breakfast before heading out for bicycling in the German countryside. While we were eating and chatting, one of the conference attendees came over, introduced himself and sat down (drawn by the sound of English and his recognition of one of the 3 of us from our sessions). A little later, another attendee came and sat on the other side. Before too long, we realized that our table had representatives from the US (Atlanta), Amsterdam, Greece, and Nigeria. We had 3 continents covered! Virtually no where else in the world can you spontaneously gather a group like this to talk about technology, programming, and weather. Just like working for an international company, it broadens your perspective on technology and other more important things.
An interesting thing happened at breakfast this morning that highlights why I like this conference so much. Terry (my colleague from Atlanta) and I planned to meet another speaker from Amsterdam who we've known for years for breakfast before heading out for bicycling in the German countryside. While we were eating and chatting, one of the conference attendees came over, introduced himself and sat down (drawn by the sound of English and his recognition of one of the 3 of us from our sessions). A little later, another attendee came and sat on the other side. Before too long, we realized that our table had representatives from the US (Atlanta), Amsterdam, Greece, and Nigeria. We had 3 continents covered! Virtually no where else in the world can you spontaneously gather a group like this to talk about technology, programming, and weather. Just like working for an international company, it broadens your perspective on technology and other more important things.
Tuesday, September 19, 2006
Application Development Isolation from its Environment
Back in my DSW days, we did a fair amount of development in Delphi (a RAD application builder from Borland), and we noticed a trend. We frequently won return business by our customers (the hallmark of a successful consulting company), but we always ran into a major hassle: re-setting up the environment. Delphi, being a component-based development environment, took advantage of a rich ecosystem of third-party components. Why write something from scratch when you can buy it, frequently with source code included? However, using third party components meant that every application development environment is subtly different. Client A uses this widget, but you have to make sure not to use it for client B, because they don't own a license for it. Conceptually (but not actually), these controls were like ActiveX or .NET components in that they were installed on the developer's machine and became part of the operating system (at least as far as the developer tool was concerned). We thought a bit about how to isolate each project from another (some project setups would occupy a week of time, getting the right Delphi version and components installed just the way we left them). The problem was one of isolation: you can't encapsulate the development environment (or the developed application) at any level lower than the operating system.
They we developed a clever solution: start building our applications in VMWare. VMWare had just gotten Really Good at that time, and we realized that we could take a generic Windows ghost and install all the necessary developer tools on a VMWare image and develop on it. The speed hit at the time wasn't terrible, and it allowed us clean-room development for each client. When that phase of the project concluded, we save the VMWare image out to a server. Two years later, when that client came back for enhancements, we started up that application's development environment just like the day we left it. This approach saved us days of downtime, and made developing for multiple clients a breeze. Client A needs some minor tweaks while I'm working on client B's application. No problem, just bounce between virtual machine images.
Why do I bring this up now? Because the exact same scenario is playing out in the .NET development space. Most third-party components either GAC themselves or have stringent licensing requirements. Virtualization has gotten pervasive now, so if you have to do development on a machine that isn't a throw-away pairing machine image, life is easier if you sandbox it into its own virtual machine. I did this out of necessity on my former .NET project because I was developing on a MacBook Pro. However, I think this is wise for any development effort in a platform (like Delphi or .NET) that can't be isolated at any level lower than the entire operating system. This isn't as big a problem with Java or Ruby because they don't irrevocably couple themselves to the operating system. This is one of the prices you pay for that tight integration with Windows that .NET gives you: you can't de-integrate when you need to.
They we developed a clever solution: start building our applications in VMWare. VMWare had just gotten Really Good at that time, and we realized that we could take a generic Windows ghost and install all the necessary developer tools on a VMWare image and develop on it. The speed hit at the time wasn't terrible, and it allowed us clean-room development for each client. When that phase of the project concluded, we save the VMWare image out to a server. Two years later, when that client came back for enhancements, we started up that application's development environment just like the day we left it. This approach saved us days of downtime, and made developing for multiple clients a breeze. Client A needs some minor tweaks while I'm working on client B's application. No problem, just bounce between virtual machine images.
Why do I bring this up now? Because the exact same scenario is playing out in the .NET development space. Most third-party components either GAC themselves or have stringent licensing requirements. Virtualization has gotten pervasive now, so if you have to do development on a machine that isn't a throw-away pairing machine image, life is easier if you sandbox it into its own virtual machine. I did this out of necessity on my former .NET project because I was developing on a MacBook Pro. However, I think this is wise for any development effort in a platform (like Delphi or .NET) that can't be isolated at any level lower than the entire operating system. This isn't as big a problem with Java or Ruby because they don't irrevocably couple themselves to the operating system. This is one of the prices you pay for that tight integration with Windows that .NET gives you: you can't de-integrate when you need to.
Monday, September 11, 2006
Thinking Different(ly)
I've fully made the switch. Instead of traveling with 2 laptops (a Dell Latitude 610 and a PowerBook G4), I've consolidated to a single machine: a 17-inch, fully loaded MacBook Pro. The tipping point for me? The ability to do real .NET development on the Mac.
Of course, I've seen and heard all the stuff about Parallels and how good it is: many orders of magnitude better than Virtual PC, which must create a virtual set of hardware on which Windows can run. Parallels (and the upcoming VMWare for the Mac) take advantage of virtualization hardware on the Intel chip, so you really do get near native speed when running Parallels inside OS X. Notice: not dual booting, but running Windows in a window inside OS X. But, I'm on a .NET project, and "it almost runs good enough to do .NET development" isn't quite enough. Thus, my hesitation up until this point to take the plunge. Well, I'm hear to say: it works as advertised. Building our project in Parallels on the Mac is essentially as fast as building it on the single processor Dell. The build time is within seconds of one another (for an 8 minute build).
But there are always things that you can't read about in reviews that still cause issues. I've been here before, and know that there are lots of little hidden gotchas. When I decided to move everything over, I reserved some time for glitches. And you know what? I got that time back, because I ran into very few minor ones and no major ones.
Here's an example of something you won't read about but is a huge deal if you are planning to use your Mac for .NET development. For a real .NET project, you must have (of course) the Windows XP operating system, a database server (MS SQL Server), and Visual Studio, including all the 3rd party components required by your project. For our application, you also need Office. How big do you make your virtual disk? This was a very important question in the VMWare days. Like "real" hardware, VMWare virtual disks (at least in the last version I used) cannot be re-sized. Once you create the disk, you are stuck with it. When using VMWare, getting that disk size right is critical. Not in Parallels. Parallels includes a utility that allows you to resize the partition. I started with a ridiculously optimistic 8 Gb drive. I quickly ran out of room. So, I used the Parallels utility to make the drive bigger. But here's the part you can't read about anywhere: once you start the virtual Windows back up, it views that new space as "unpartitioned", meaning that you can't use it for anything yet. But, Windows on Parallels is so Windows that you can run Partition Magic on that newly resized virtual disk and make your main disk bigger. I've done it 3 times now (and am now up to a 20Gb partition for our project).
Here's another illustration of the Window-y-ness of Parallels on OS X. I had some problems with the database setup, and Brian (our DBA) was kind enough to take a look for me. He's in London; I'm in Chicago. I started up Windows, gave him the IP address assigned by DHCP in Chicago, and he VPNed into our network and ran my Windows install via Remote Desktop. He never realized (until I told him later) that he was running Windows on top of OS X.
This represents a watershed event. The MacBook Pro + OS X (and it's siblings) are now the only machines that run every modern operating system. For consultants, that's huge. We can now go into any organization, find out what they are running, and fit in exactly. Your servers are running Ubuntu? No problem, I can create a virtualized version here on my machine. Red Hat, Windows Server 2003, Vista...you name it, I can now run it. The Mac has changed from an artistic, boutiquey machine to the ultimate Swiss-army chain saw for consultants. If I were Dell, I'd be worried. OS X and the wonderfully designed hardware make for a significantly better user experience. And now it's the power users machine of choice. Maybe I should buy some Apple stock...
Of course, I've seen and heard all the stuff about Parallels and how good it is: many orders of magnitude better than Virtual PC, which must create a virtual set of hardware on which Windows can run. Parallels (and the upcoming VMWare for the Mac) take advantage of virtualization hardware on the Intel chip, so you really do get near native speed when running Parallels inside OS X. Notice: not dual booting, but running Windows in a window inside OS X. But, I'm on a .NET project, and "it almost runs good enough to do .NET development" isn't quite enough. Thus, my hesitation up until this point to take the plunge. Well, I'm hear to say: it works as advertised. Building our project in Parallels on the Mac is essentially as fast as building it on the single processor Dell. The build time is within seconds of one another (for an 8 minute build).
But there are always things that you can't read about in reviews that still cause issues. I've been here before, and know that there are lots of little hidden gotchas. When I decided to move everything over, I reserved some time for glitches. And you know what? I got that time back, because I ran into very few minor ones and no major ones.
Here's an example of something you won't read about but is a huge deal if you are planning to use your Mac for .NET development. For a real .NET project, you must have (of course) the Windows XP operating system, a database server (MS SQL Server), and Visual Studio, including all the 3rd party components required by your project. For our application, you also need Office. How big do you make your virtual disk? This was a very important question in the VMWare days. Like "real" hardware, VMWare virtual disks (at least in the last version I used) cannot be re-sized. Once you create the disk, you are stuck with it. When using VMWare, getting that disk size right is critical. Not in Parallels. Parallels includes a utility that allows you to resize the partition. I started with a ridiculously optimistic 8 Gb drive. I quickly ran out of room. So, I used the Parallels utility to make the drive bigger. But here's the part you can't read about anywhere: once you start the virtual Windows back up, it views that new space as "unpartitioned", meaning that you can't use it for anything yet. But, Windows on Parallels is so Windows that you can run Partition Magic on that newly resized virtual disk and make your main disk bigger. I've done it 3 times now (and am now up to a 20Gb partition for our project).
Here's another illustration of the Window-y-ness of Parallels on OS X. I had some problems with the database setup, and Brian (our DBA) was kind enough to take a look for me. He's in London; I'm in Chicago. I started up Windows, gave him the IP address assigned by DHCP in Chicago, and he VPNed into our network and ran my Windows install via Remote Desktop. He never realized (until I told him later) that he was running Windows on top of OS X.
This represents a watershed event. The MacBook Pro + OS X (and it's siblings) are now the only machines that run every modern operating system. For consultants, that's huge. We can now go into any organization, find out what they are running, and fit in exactly. Your servers are running Ubuntu? No problem, I can create a virtualized version here on my machine. Red Hat, Windows Server 2003, Vista...you name it, I can now run it. The Mac has changed from an artistic, boutiquey machine to the ultimate Swiss-army chain saw for consultants. If I were Dell, I'd be worried. OS X and the wonderfully designed hardware make for a significantly better user experience. And now it's the power users machine of choice. Maybe I should buy some Apple stock...
Saturday, September 02, 2006
Pairing Everywhere
The more I pair program, the more I'm convinced that two (compatible) people always produce better results than just one. I know that pair programming is the best way to write code. This started me thinking about other creative artifacts that might benefit from pairing.
There are already some pretty famous pairs. Rogers and Hammerstein come to mind. One of the greatest series of history books, The Story of Civilization, was written by a pair of authors, Will and Ariel Durant. Because they were written in the 1920's, only Will's name appears on the first few, but he eventually acknowledged his wife in the later books as a co-author. Some great authors were essentially pairing with their editors. Numerous examples exist of great writers whose works were made better because of a strong willed editor: Theodore Dreiser, Ernest Hemingway, and on and on.
To this end, my friend and colleague Joe O'Brien and I tried a new trick this year at ThoughtWorks Away Day: pair teaching. He and I used 2 computers, 2 projectors, and one topic (Ruby for ThoughtWorkers Who Don't Know Ruby But Want to Know Why It Rocks: Learning Ruby Through Unit Testing). In the end, the sum was greater than the parts. It was a frantic 1 hour presentation, with something happening constantly. After the smoke cleared, another ThoughtWorker said that he really enjoyed it because his mind only wandered for about 4 minutes total during the entire time, and suggested that if we hire a clown to walk through the audience, juggling, and repeating our key points, that we would have held 100% of his attention. High praise, indeed.
There are already some pretty famous pairs. Rogers and Hammerstein come to mind. One of the greatest series of history books, The Story of Civilization, was written by a pair of authors, Will and Ariel Durant. Because they were written in the 1920's, only Will's name appears on the first few, but he eventually acknowledged his wife in the later books as a co-author. Some great authors were essentially pairing with their editors. Numerous examples exist of great writers whose works were made better because of a strong willed editor: Theodore Dreiser, Ernest Hemingway, and on and on.
To this end, my friend and colleague Joe O'Brien and I tried a new trick this year at ThoughtWorks Away Day: pair teaching. He and I used 2 computers, 2 projectors, and one topic (Ruby for ThoughtWorkers Who Don't Know Ruby But Want to Know Why It Rocks: Learning Ruby Through Unit Testing). In the end, the sum was greater than the parts. It was a frantic 1 hour presentation, with something happening constantly. After the smoke cleared, another ThoughtWorker said that he really enjoyed it because his mind only wandered for about 4 minutes total during the entire time, and suggested that if we hire a clown to walk through the audience, juggling, and repeating our key points, that we would have held 100% of his attention. High praise, indeed.
Friday, August 25, 2006
Categorizing Creative Genius
I just read a fascinating article in the July Wired magazine about creative genius. The subject, an economist named David Galenson, has correlated age with perceived value in all sorts of creative fields, and has identified 2 curves. One, which he dubs "Concepualists", tend to peak early in their careers. For example, even though Picasso lived into his 90's, his most cited works in art history and other books were done before he was 30. Mark Rothko, (one of my favorites), did his most cited work the year he died, when he was 59. Galenson calls these guys "Experimentalists". He has done this correlation over painting, fiction, economists, music, and other fields. He believes that 2 distinct flavors of genius exist: one that manifests itself early, with bold, field-changing paradigm shifts (concepualist) and another, slower, accumulated genius (the experimentalist).
This instantly applies to other fields that he hasn't studied, like physics. I've often wondered why so many brilliant, earth shattering discoveries are made by young men Newton, Einstein, and Feynman were quite young when they produced their landmark works). However, if you look at someone like Stephen Hawking, he's still producing significant work. I think this is a great topic, one that resonates with observations I've made but never correlated myself. His book is named Old Masters and Young Geniuses: The Two Lifecycles of Artistic Creativity, and it's jumping to the top of my reading list with a bullet.
This instantly applies to other fields that he hasn't studied, like physics. I've often wondered why so many brilliant, earth shattering discoveries are made by young men Newton, Einstein, and Feynman were quite young when they produced their landmark works). However, if you look at someone like Stephen Hawking, he's still producing significant work. I think this is a great topic, one that resonates with observations I've made but never correlated myself. His book is named Old Masters and Young Geniuses: The Two Lifecycles of Artistic Creativity, and it's jumping to the top of my reading list with a bullet.
Sunday, August 20, 2006
Technology Snake Oil Part 8: Service Pack Shell Game
If you could see my face, you would see shock, dumbfoundment, and disgust. It pains me to
even write about something as stupid as this, but it keeps rearing its head. The
majority of my recent clients and someone I talked to casually from another
company recently are relying on one poisonous meme, which seems to be spreading.
The very bad idea: "We never deploy anything until the first service pack is
released".
Let's think about this for a second. If a vendor produced the
most perfect software ever conceived by mankind, there would never be a service
pack, thus none of these companies would ever deploy it. On the other hand, if I
release a really stinky version of some software that requires a service pack
after a week, it now meets this unassailable standard of deployability.
Two factors have led to this smelly idea. The first is just pure laziness on the
part of the decision makers who decide when things get deployed. Regardless of
the service pack level, you should always evaluate software on its merits. A
prescription like the Service Pack Shell Game ignores important factors in
software and tries to find a metric that indicates quality. This is not even
close. When Windows NT Service Pack 1 was released, it was a disaster. Service
Pack 2 basically rolled back all the changes that SP1 wrought. That's why, to
this day, you still see software that requires NT SP3, because that was the
first real service pack that actually fixed anything.
The other reason this is happening is both more subtle and dangerous. Have we really gotten to the
point where we distrust commercial software this much? It's because vendors have
consistently released software that is not ready for prime time and told us that
it's of shipping quality. Companies even apply this selection process to open
source software now. Open source has no marketing department pushing releases
out the door. Generally, open source software ships when it is ready. Thus, most
open source has fewer "service packs" than commercial software. Yet this same
flawed prescription is often applied to it. Software, no matter what the source,
should be vetted based on it's quality, which should be determined by (as much
as possible) objective means. Choosing a random metric like "after the first
service pack" guarantees you'll get hit-and-miss quality software.
even write about something as stupid as this, but it keeps rearing its head. The
majority of my recent clients and someone I talked to casually from another
company recently are relying on one poisonous meme, which seems to be spreading.
The very bad idea: "We never deploy anything until the first service pack is
released".
Let's think about this for a second. If a vendor produced the
most perfect software ever conceived by mankind, there would never be a service
pack, thus none of these companies would ever deploy it. On the other hand, if I
release a really stinky version of some software that requires a service pack
after a week, it now meets this unassailable standard of deployability.
Two factors have led to this smelly idea. The first is just pure laziness on the
part of the decision makers who decide when things get deployed. Regardless of
the service pack level, you should always evaluate software on its merits. A
prescription like the Service Pack Shell Game ignores important factors in
software and tries to find a metric that indicates quality. This is not even
close. When Windows NT Service Pack 1 was released, it was a disaster. Service
Pack 2 basically rolled back all the changes that SP1 wrought. That's why, to
this day, you still see software that requires NT SP3, because that was the
first real service pack that actually fixed anything.
The other reason this is happening is both more subtle and dangerous. Have we really gotten to the
point where we distrust commercial software this much? It's because vendors have
consistently released software that is not ready for prime time and told us that
it's of shipping quality. Companies even apply this selection process to open
source software now. Open source has no marketing department pushing releases
out the door. Generally, open source software ships when it is ready. Thus, most
open source has fewer "service packs" than commercial software. Yet this same
flawed prescription is often applied to it. Software, no matter what the source,
should be vetted based on it's quality, which should be determined by (as much
as possible) objective means. Choosing a random metric like "after the first
service pack" guarantees you'll get hit-and-miss quality software.
Friday, August 18, 2006
ejbKarmaCallback()
When you work with a noxious technology enough, it eventually comes back to bite you. Call it software development karma. While I was at OSCON in Portland, the first hotel room where I was placed had massive problems connecting to the Internet. It was wired access, so there was something related to my room that was causing the problem. I endured several maintenance guys and several phone calls with the actual provider. You all know the drill intimately.
Anyway, at one point, it was declared "Fixed!", and I was instructed to point my faithful browser to the Internet. Lo and behold, Software Karma decreed that it was not to be. I got the following error, captured here in all its public glory.
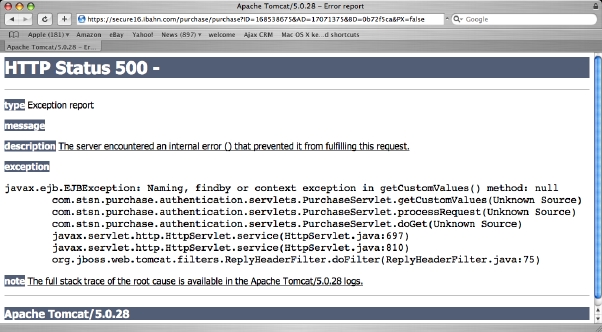
Gaaaaaah! I now know waaaayyy more about their network infrastructure than I would like. They are using Tomcat and EJB's...to connect me to the Internet???!? I'm sure this is exactly the kind of application the EJB designers had in mind when they birthed this technology. Do we think that maybe this is total overkill? Couldn't the same be done with a simple web application backed by a database. Sigh. That's what I get for dabbling in evil -- sometimes it comes back to haunt you in the strangest places.
Anyway, at one point, it was declared "Fixed!", and I was instructed to point my faithful browser to the Internet. Lo and behold, Software Karma decreed that it was not to be. I got the following error, captured here in all its public glory.
Gaaaaaah! I now know waaaayyy more about their network infrastructure than I would like. They are using Tomcat and EJB's...to connect me to the Internet???!? I'm sure this is exactly the kind of application the EJB designers had in mind when they birthed this technology. Do we think that maybe this is total overkill? Couldn't the same be done with a simple web application backed by a database. Sigh. That's what I get for dabbling in evil -- sometimes it comes back to haunt you in the strangest places.
Sunday, August 13, 2006
Scumbag Spammers
If you have posted a comment to my blog lately, you've noticed that I've turned on the "Word Verification" feature of Blogspot. It's because of the scum of the earth, spammers. They've started posting spam comments (spamments?) to blogs. How clever. How annoying. How I hope they choke on their own vomit as they slide under a gas truck.
Saturday, August 12, 2006
Search Trumps Hiearchies
I wrote a while back about Pervasive Search, and how it changed the way I find things. I find myself using search more and more versus navigating hierarchies. As developers, we tend to create lots of files, in regular strict hierarchical structure (in fact, I've been blogging about namespaces vs. packages recently as well). File system paths are now too cumbersome to endure. Instead of walking through Explorer or the tree in my IDE, I'm using search.
I use search at 2 levels. Within the IDE, I use the brilliant feature in both IntelliJ and ReSharper to "Find File" (keyboard shortcut: Ctrl-N). This lets you type in the name (or partial) name of a file and open it in the editor. Better yet, it finds patterns of capital letters in names. So, if you are looking for the
The other place I've been using search a lot is the filesystem, when looking for either a file on which to perform some operation (like Subversion log) or looking for some content within a file. Google Desktop Search has gotten better and better. You can now invoke it with the key chord of hitting Ctrl twice. And, you can download a plug-in that allows you to search through any type of file you want, including program and XML documents. Once you've found the file in question, you can right-click on the search result and open the containing folder. This is the only way to get to some file buried deep in some package or directory structure. My coding pair and I have started using this heavily, and it has sped us up. And, it eliminates annoying repetitive tasks like digging through the rubble of the filesystem looking for a gold nugget.
I use search at 2 levels. Within the IDE, I use the brilliant feature in both IntelliJ and ReSharper to "Find File" (keyboard shortcut: Ctrl-N). This lets you type in the name (or partial) name of a file and open it in the editor. Better yet, it finds patterns of capital letters in names. So, if you are looking for the
ShoppingCartMemento class, you could type "SCM", and "Find File" will find it. Highly addictive. And, it works equally well in IntelliJ and Visual Studio with ReSharper (and my Eclipse friends tell me it has made it there as well).The other place I've been using search a lot is the filesystem, when looking for either a file on which to perform some operation (like Subversion log) or looking for some content within a file. Google Desktop Search has gotten better and better. You can now invoke it with the key chord of hitting Ctrl twice. And, you can download a plug-in that allows you to search through any type of file you want, including program and XML documents. Once you've found the file in question, you can right-click on the search result and open the containing folder. This is the only way to get to some file buried deep in some package or directory structure. My coding pair and I have started using this heavily, and it has sped us up. And, it eliminates annoying repetitive tasks like digging through the rubble of the filesystem looking for a gold nugget.
Thursday, August 03, 2006
Partial Classes
When I first saw that .NET 2 supported partial classes, I groaned. It
looked like a language feature that helps one thing and hurts a dozen
more, once people start abusing it. However, I've come around to appreciate (and dare I say it, like) partial classes. They are obviously useful for code generation (which is why, I suspect) they were added in the first place). However, they are also handy for other problems.
Testing is one place where partial classes offer a better solution than the one offered by Visual Studio.NET 2005. In VS.NET, if you want to use MS-Test to test a private method, the tool uses code generation (without partial classes) to create a public proxy method that turns around and calls the private method for you using reflection. This is not a big surprise; the JUnitX add-ins in Java help you do the same thing. But using code gen for this is a smell: if you change your private method using reflection, the generated code isn't smart enough to change, so you have to do code gen again, potentially overwriting some of the code you've added. Yuck.
Here's a better solution. I should add parenthetically that I don't usually bother testing private methods (especially if I have code coverage) because the public methods will exercise the private ones (otherwise, the private methods shouldn't be there). However, when doing TDD, I sometimes want to test a complext private method. And partial classes work great for this. The example I have here is a console application that does some number factoring (why isn't important in this context). I have a method
Rather than use code gen to test the method, I've made the
I like this because it allows me to test the private method without any messy code generation, reflection, or other smelly work-arounds. Partial classes make great test fixtures because they have access to the internal workings of the class but don't have to reside in the same file. It's dangerous to pile infrastructure on new features like this (especially scaffolding-type infrastructure like classes), but this one seems like a more elegant solution to the problem at hand than stacks of code generation.
looked like a language feature that helps one thing and hurts a dozen
more, once people start abusing it. However, I've come around to appreciate (and dare I say it, like) partial classes. They are obviously useful for code generation (which is why, I suspect) they were added in the first place). However, they are also handy for other problems.
Testing is one place where partial classes offer a better solution than the one offered by Visual Studio.NET 2005. In VS.NET, if you want to use MS-Test to test a private method, the tool uses code generation (without partial classes) to create a public proxy method that turns around and calls the private method for you using reflection. This is not a big surprise; the JUnitX add-ins in Java help you do the same thing. But using code gen for this is a smell: if you change your private method using reflection, the generated code isn't smart enough to change, so you have to do code gen again, potentially overwriting some of the code you've added. Yuck.
Here's a better solution. I should add parenthetically that I don't usually bother testing private methods (especially if I have code coverage) because the public methods will exercise the private ones (otherwise, the private methods shouldn't be there). However, when doing TDD, I sometimes want to test a complext private method. And partial classes work great for this. The example I have here is a console application that does some number factoring (why isn't important in this context). I have a method
theFactorsFor() that returns the factors for an integer. Here is the PerfectNumberFinder class, including the method in question:namespace PerfectNumbers {
internal partial class PerfectNumberFinder {
public void executePerfectNumbers() {
for (int i = 2; i < 500; i++) {
Console.WriteLine(i);
if (isPerfect(i))
Console.WriteLine("{0} is perfect", i);
}
}
private int[] theFactorsFor(int number) {
int sqrt = (int) Math.Sqrt(number) + 1;
List<int> factors = new List<int>(5);
factors.Add(1);
factors.Add(number);
for (int i = 2; i <= sqrt; i++)
if (number % i == 0) {
if (! factors.Contains(i))
factors.Add(i);
if (!factors.Contains(number/i))
factors.Add(number/i);
}
factors.Sort();
return factors.ToArray();
}
private bool isPerfect(int number) {
return number == sumOf(theFactorsFor(number)) - number;
}
private int sumOf(int[] factors) {
int sum = 0;
foreach (int i in factors)
sum += i;
return sum;
}
}
}
Rather than use code gen to test the method, I've made the
PerfectNumberFinder class a partial class. The other part of the partial is the NUnit TestFixture, shown here:
namespace PerfectNumbers {
[TestFixture]
internal partial class PerfectNumberFinder {
[Test]
public void Get_factors_for_number() {
int[] actual;
Dictionary<int, int[]> expected =
new Dictionary<int, int[]>();
expected.Add(3, new int[] {1, 3});
expected.Add(6, new int[] {1, 2, 3, 6});
expected.Add(8, new int[] {1, 2, 4, 8});
expected.Add(16, new int[] {1, 2, 4, 8, 16});
expected.Add(24, new int[] {1, 2, 3, 4, 6, 8, 12, 24});
foreach (int f in expected.Keys) {
actual = theFactorsFor(f);
for (int i = 0; i < expected[f].Length; i++)
Assert.AreEqual(expected[f][i], actual[i],
"Expected not equal");
}
}
}
}
I like this because it allows me to test the private method without any messy code generation, reflection, or other smelly work-arounds. Partial classes make great test fixtures because they have access to the internal workings of the class but don't have to reside in the same file. It's dangerous to pile infrastructure on new features like this (especially scaffolding-type infrastructure like classes), but this one seems like a more elegant solution to the problem at hand than stacks of code generation.
Tuesday, August 01, 2006
Pontificating at OSCON
I gave a talk as OSCON last week on Building Internal DSLs in Ruby. Apparently, there is a fair amount of interest in this subject: I was in one of the small rooms, but it was packed to the rafters, with standing room only along the back and side walls. I didn't realize it, but John Lam took a snapshot of me in action and posted it to his blog:  .
.
It's tough to get a good shot while someone is talking, so it shows that John is both a formidable Ruby/.NET guy and a talented photographer!
. It's tough to get a good shot while someone is talking, so it shows that John is both a formidable Ruby/.NET guy and a talented photographer!
The Fact of the JMatter
Several years ago, some brilliant designers created Naked Objects, a Java framework that generates applications from domain objects. You supply the POJOs with behavior, point Naked Object at them, and you have a full-blown Swing application that allows you to edit, insert, delete, and browse the objects and their relationships. You could literally create sparse, functional applications in minutes. However, Naked Objects never got much beyond a proof of concept. The automatically generated applications were utilitarian but uninspiring.
Fast forward to now. Eitan Suez, one of my fellow No Fluff, Just Stuff
speakers, has taken the Naked Object idea and run with it. He has created the JMatter framework (found here). It takes the concepts of Naked Objects and updates it to the here and now. JMatter applications still auto-generate from POJOs, but the user interface and interactions are very rich. The sample application that appears on the JMatter web site literally took less than 2 hours to create; written by hand, it equates to developer-weeks worth of effort. It also illustrates a growing trend in development: creating framework and scaffolding code automatically, freeing developers to focus more on producing applications. We've seen this approach done well in Ruby on Rails. JMatter shows that you can apply the same concepts to Swing development. Eitan has released JMatter with a MySQL-style license, so it's worth jumping over to his site to get a preview of the future.
Fast forward to now. Eitan Suez, one of my fellow No Fluff, Just Stuff
speakers, has taken the Naked Object idea and run with it. He has created the JMatter framework (found here). It takes the concepts of Naked Objects and updates it to the here and now. JMatter applications still auto-generate from POJOs, but the user interface and interactions are very rich. The sample application that appears on the JMatter web site literally took less than 2 hours to create; written by hand, it equates to developer-weeks worth of effort. It also illustrates a growing trend in development: creating framework and scaffolding code automatically, freeing developers to focus more on producing applications. We've seen this approach done well in Ruby on Rails. JMatter shows that you can apply the same concepts to Swing development. Eitan has released JMatter with a MySQL-style license, so it's worth jumping over to his site to get a preview of the future.
Friday, July 21, 2006
DSLing @ OSCON
I'm off to Portland, Oregon next week (my first ever trip to Oregon, so I can knock that off my travel map at World66), speaking at my first OSCON. I'm doing a talk on Building DSLs in Ruby, based on material that Jeremy, Joe, Zak, and I have produced for the Pragmatic Press book upon which we are working (slowly). I'm also signed up for some pre-conferecnce tutorials, including a 4 hour talk about VIM (I just had to see someone use VIM for 4 hours - I expect it to be quite impressive).
If you are in Portland, look me up. I speak on Thursday, and have some meetings on the other days, but mostly I'll be hanging around. A bunch of my No Fluff friends will also be there, so there may be some Magic games or even some Settlers of Catan.
If you are in Portland, look me up. I speak on Thursday, and have some meetings on the other days, but mostly I'll be hanging around. A bunch of my No Fluff friends will also be there, so there may be some Magic games or even some Settlers of Catan.
Tuesday, July 18, 2006
Boy Scout Capabilities
I was having a conversation with a co-worker today whose first name prominently features the letter "Z". Our topic: how does a company like ThoughtWorks, which hires lots of experienced developers, determine at what level that person should be hired. Some candidates are cut and dried: you can tell when you interview them. But what about the developers who fall through cracks? Maybe they are an ace developer in 4 languages, but they've never done agile. Or, a great militant Agilist, but they have never done test-driven development. As a company, we need 2 things: how to categorize these folks upon hiring and, more importantly, how to fill in knowledge gaps after they arrive. After all, the ultimate goal is to create well rounded ThoughtWorkers, who are good at all the things we value highly.
In talking about this subject, I came up with the idea I called the Merit Badge approach. Just like in the Boy Scouts, when a scout moved from one troop to another, you knew their rank instantly because of the acquired merit badges. Each merit badge had deterministic acceptance criteria, and you knew that the scout in question had mastered the badge criteria before moving to the next one. A certain number of badges, covering a certain set of areas, lead to increased rank. If a company like ThoughtWorks wants all Eagle scouts, we must invest in our rookie scouts to enable them to get to that level. We should have technology merit badges. If we get a good candidate that knows everything but TDD, we should send them to a TDD training class or similar until they have mastered that skill. Advancements in the technical ranks becomes an exercise is acquiring useful skills. That keeps the process more objective and allows for clear ascension paths through the technical ranks. The People People can track the merit badges and recommend training and mentoring for the next milestone.
And, we'd all get to wear those cool sashes!
In talking about this subject, I came up with the idea I called the Merit Badge approach. Just like in the Boy Scouts, when a scout moved from one troop to another, you knew their rank instantly because of the acquired merit badges. Each merit badge had deterministic acceptance criteria, and you knew that the scout in question had mastered the badge criteria before moving to the next one. A certain number of badges, covering a certain set of areas, lead to increased rank. If a company like ThoughtWorks wants all Eagle scouts, we must invest in our rookie scouts to enable them to get to that level. We should have technology merit badges. If we get a good candidate that knows everything but TDD, we should send them to a TDD training class or similar until they have mastered that skill. Advancements in the technical ranks becomes an exercise is acquiring useful skills. That keeps the process more objective and allows for clear ascension paths through the technical ranks. The People People can track the merit badges and recommend training and mentoring for the next milestone.
And, we'd all get to wear those cool sashes!
CJUG Redux
I'm speaking at the Chicago Java Users Group tonight (the Downtown one), giving my No Fluff, Just Stuff talk entitled The Productive Programmer, based on material from the book that David Bock and I are (slowly) working on for Pragmatic Press. It's completely technology agnostic, so if any .NET guys want to crash the party, feel free (sure to generate lively conversation). First-time attendees pay no dues or admission, so that makes this a really, really cheap date for you and your significant other.
Sunday, July 16, 2006
Ubiqui-GPS
GPS technology has suddenly gotten really cheap, and I've taken advantage of it in 2 big ways. First, I managed to get a GPS watch from woot.com for a great price, which includes the arm-mounted GPS receiver, for urban running. It's so accurate, it provides miles per hour in real time while you are running. The other cool use of GPS is the updated version of Microsoft's Streets and Trips. This mapping software used to be nice-to-have for road warriors, now it has moved to essential because it includes a small GPS receiver. You arrive in a foreign city with only the hotel address, punch it in, and you have turn-by-turn directions, spoken via your laptop's speakers, with the traced-out route on the screen. Having Streets and Trips on a laptop is better than having one of the little Palm-sized units because a) I'm taking my laptop with me everywhere anyway and b)the screen on the laptop is much bigger and nicer. The only downside is that you've got to be within a couple of hours of your destination or have a car adaptor for your laptop.
GPS has reached the point where it is cheap, available, and plentiful. My friend Scott Davis has a nice keynote presentation at No Fluff, Just Stuff this year where he argues that location based services will be very important in the near term. The combined technologies of cheap GPS, mashup applications that leverage tools like Google maps, and the growing awareness in software of actual location suggests rich applications beyond what we've got now. If we can just get all this down to the phone level, the only thing left will be flying cars.
GPS has reached the point where it is cheap, available, and plentiful. My friend Scott Davis has a nice keynote presentation at No Fluff, Just Stuff this year where he argues that location based services will be very important in the near term. The combined technologies of cheap GPS, mashup applications that leverage tools like Google maps, and the growing awareness in software of actual location suggests rich applications beyond what we've got now. If we can just get all this down to the phone level, the only thing left will be flying cars.
Thursday, July 13, 2006
EKON X
I've done this conference so many times, it's a natural part of the year. I look forward to this great conference and my good friends in Germany, who I see only once a year. Terry and I will also be running our 5th Berlin Marathon before the conference. The happy conjunction between EKON and Berlin Marathon is great. I'm looking forward to it!
Sunday, July 09, 2006
The Persistent Persistence Question
On my current project, we faced the inevitable, persistent, annoying question of which persistence framework to use. We boiled it down to 2 choices: nHibernate or iBatis. As usual, it was not a cut-and-dried decision, as each had their strengths. nHibernate, being a meta-data mapper, writes all the annoying SQL for you, which is a huge time saver...when it can. However, when talking to complex legacy schemas, nHibernate gets tougher and tougher to configure. iBatis, on the other hand, doesn't try to generate your SQL. It just takes care of the object-relation mapping for you, from SQL you supply. That makes it much better for complex schemas, stored procedures, etc. So, which to use?
In the end, we chose both! We estimated that maintaining separate configurations would take a little time, but it would save us time on both sides: letting nHibernate do its magic when it can, and falling back to iBatis when it made more sense. It has worked out very well. We have a couple of very complex queries being handled gracefully by iBatis, and nHibernate handles all the simple persistence in the application. Sometimes, seemingly mutually exclusive options actually complement one another.
In the end, we chose both! We estimated that maintaining separate configurations would take a little time, but it would save us time on both sides: letting nHibernate do its magic when it can, and falling back to iBatis when it made more sense. It has worked out very well. We have a couple of very complex queries being handled gracefully by iBatis, and nHibernate handles all the simple persistence in the application. Sometimes, seemingly mutually exclusive options actually complement one another.
Wednesday, June 28, 2006
Fixing Subversion with Command Line Judo
As many of you know, David Bock and I are writing a book about programmer productivity, which includes a fair amount of command line judo. Here's a little piece that I developed for my project.
Occasionally, Subversion breaks with an error that references a path that includes /!svn/ and another line that talks about status 200. (Sorry, I don't have an exact replica right now because it's fixed. I’ll try to capture one in the wild next time I find one.) This seems to happen when someone checks in a binary that is being used by another application: Word document, Excel spreadsheet, or PDB file.
When this happens, you must go through your directory structure to identify the bad file. This is cumbersome (more in a second about this). Once you have found the bad file, remove it from the repository view (i.e., remove it directly from the repository, not your local file system) and do an update. To find the file, you must go to every directory in your local copy of the repository and do an update in that directory. The first directory whose update breaks holds the problem file, which you must find by trial and error. You can do this with Tortoise, but it takes forever.
If you have the foresight to have Cygwin (and therefore the Bash shell) on your machine, you can issue this command (in Bash) from the root directory of your repository:
find . -type d | grep -v "/.svn" | xargs svn up
This command finds every directory, eliminates the ".svn" folders, and pumps the directory name into "svn up". The first directory that breaks when this command executes is your problem folder. Problem solved.
My educated guess on our repository is that it would take 20 minutes to use Tortoise to update every folder, one at a time. It took me about 10 minutes to develop this little bit of command line judo. So, in this case, automating the solution actually took less time than the brute force approach. But, even if the automated approach takes longer to develop, you have a tool for the next time it happens.
Stay tuned for a bunch more stuff like this when we get The Productive Programmer done!
Wednesday, June 21, 2006
Cheeburger, Cheeburger, cheeps, pepksi
One of my coworkers doesn't have a blog, but he successfully identified another sacred cow that we're converting to cheeburgers on our project. Yet, he's so altruistic, he won't take credit for the idea, saying that it's Marjorie's idea instead. So that he can remain anonymous, I'll just call him Zak T. No, that's too obvious, let's call him Z Tamsen instead.
Zak's sacred cow is the convention in the .NET world of using Pascal casing for namespaces, which is a terrible idea. We've already run into situations where a namespace clashes with a class name, which is annoying. So, we've decided to make all our namespaces all lower case, ala Java, with underscores to separate logical names (very un-ala Java).
Namespaces in .NET are particularly broken, and not just the capitalization convention. This is one of the things that Java got really right, but in a very subtle way. One of the early annoyances for most Java developers is learning the concept of a root directory, and how the package names of your code must match up to the directory structure. Once you grok that concept, though, it makes perfect sense. Only much later do you figure out that this is one of the subtle elegances of the Java language. Because the package structure is tied to the underlying directory structure, it is difficult to create class names that overlap because the OS won't let you create 2 classes by the same name in the same directory. Score one for Java, leveraging the OS to prevent headaches for developers. Of course, with the advent of virtual directory structures in JAR files, you can now create conflicts, but it is thankfully still rare.
Namespaces in .NET have no such useful restrictions. It is trivially easy to create name conflicts because the namespace is just an arbitrary string. Most of the .NET developers I know (especially if they've done any Java) use the useful "namespace must match directory structure" convention (with less restrictions on the actual root folder). In fact, one of my colleagues, Yasser, has created a very useful utility called Namespacer that verifies that your .NET class' namespace matches the directory structure. After some use on our project, he's planning to open source it. Short of fixing namespaces in .NET, at least there is a way to verify the adherence to a useful convention.
Zak's sacred cow is the convention in the .NET world of using Pascal casing for namespaces, which is a terrible idea. We've already run into situations where a namespace clashes with a class name, which is annoying. So, we've decided to make all our namespaces all lower case, ala Java, with underscores to separate logical names (very un-ala Java).
Namespaces in .NET are particularly broken, and not just the capitalization convention. This is one of the things that Java got really right, but in a very subtle way. One of the early annoyances for most Java developers is learning the concept of a root directory, and how the package names of your code must match up to the directory structure. Once you grok that concept, though, it makes perfect sense. Only much later do you figure out that this is one of the subtle elegances of the Java language. Because the package structure is tied to the underlying directory structure, it is difficult to create class names that overlap because the OS won't let you create 2 classes by the same name in the same directory. Score one for Java, leveraging the OS to prevent headaches for developers. Of course, with the advent of virtual directory structures in JAR files, you can now create conflicts, but it is thankfully still rare.
Namespaces in .NET have no such useful restrictions. It is trivially easy to create name conflicts because the namespace is just an arbitrary string. Most of the .NET developers I know (especially if they've done any Java) use the useful "namespace must match directory structure" convention (with less restrictions on the actual root folder). In fact, one of my colleagues, Yasser, has created a very useful utility called Namespacer that verifies that your .NET class' namespace matches the directory structure. After some use on our project, he's planning to open source it. Short of fixing namespaces in .NET, at least there is a way to verify the adherence to a useful convention.
Sunday, June 18, 2006
Being Productive in Cincinnati
I'm speaking at the Cincinnati Java User's Group (CINJUG) on Monday, June 19th. I'll be presenting my talk The Productive Programmer, based on the book upon which David Bock and I are diligently but slowly working. This has become a pretty popular talk with both user groups and at No Fluff, Just Stuff shows, and I keep finding more stuff to cram into it. Soon, I'm going to have to start pruning the tips or convert it into a Part 1, Part 2 affair. If you are in Cincy, stop in and say "Hi".
Tuesday, May 30, 2006
Practices of an Agile Developer
I just finished reading Practices of an Agile Developer by Venkat Subramaniam and Andy Hunt. What a great book! I found myself nodding vigorously on virtually every page. For developers new to agility, this is an invaluable resource. And, to those of us who have been in the agile space for a while, it's good to see smart people proselytizing the same stuff I preach all the time. I particularly like the format Venkat and Andy have chosen, presenting common wisdom at the start of each section, then thoroughly debunking it in the body of the section.
Even if you are already a die-hard agilista, this book is a worth read. Highly recommended.
Even if you are already a die-hard agilista, this book is a worth read. Highly recommended.
Monday, May 29, 2006
Improving Agile Communication using Old Tools
By popular demand, I'm blogging about a communication tool we're using on our current project. I've discussed this in my Productive Programmer talk at No Fluff, Just Stuff, and I've answered the Expert Panel question of "What is your latest favorite productivity tool" with this answer. Several people have asked me follow-on questions, so I thought I'd blog about it.
One of the difficulties in distributed agile development is keeping the communication link strong between the geographically (and time zone) separated teams. We are trying hard on our current project but still fall well short of the ideal. We do have some bright spots, though. The primary communication medium between the developers is a wiki we set up for the project. For a while, we attempted to type in really comprehensive summaries of each day's development work. However, we eventually realized that we were duplicating effort: we already put detailed comments for our check-ins to Subversion. So, we had one of our temporary resources cook up the following little developer shim.
He created a tool called SVN2WIKI. It uses the SVN post-commit hook to harvest the comment of the code just checked in. It then posts those comments to the Wiki, creating a dated page if one doesn't exist or adding to the page already there if it does. The Wiki we're using (Instiki) offers an RSS feed for all changed pages. So, we installed an RSS Reader (RssBandit) on the developer workstations. Now, when a developer sits down, he or she can get an up-to-the-minute summary of all the stuff that has happened to the code base since the last time he or she looked. Because it's an RSS reader, it keeps track of what you've already read. This is a great way to keep up to date at a really detailed level for what is happening to the code base.
This hasn't eliminated the need to create daily summary pages, but these can be much more terse, and focus on outstanding questions across the ocean. The Wiki contains a living history of the project, told one check-in at a time. For those who say that agile projects don't keep documentation, the Wiki on our project is a living, breathing history of the project at a really detailed level.
Our SVN2WIKI tool is a good example of piecing together a bunch of old and common technologies (SVN, Instiki, RSS) to create a great time saver for developers while improving the toughest part of our project.
One of the difficulties in distributed agile development is keeping the communication link strong between the geographically (and time zone) separated teams. We are trying hard on our current project but still fall well short of the ideal. We do have some bright spots, though. The primary communication medium between the developers is a wiki we set up for the project. For a while, we attempted to type in really comprehensive summaries of each day's development work. However, we eventually realized that we were duplicating effort: we already put detailed comments for our check-ins to Subversion. So, we had one of our temporary resources cook up the following little developer shim.
He created a tool called SVN2WIKI. It uses the SVN post-commit hook to harvest the comment of the code just checked in. It then posts those comments to the Wiki, creating a dated page if one doesn't exist or adding to the page already there if it does. The Wiki we're using (Instiki) offers an RSS feed for all changed pages. So, we installed an RSS Reader (RssBandit) on the developer workstations. Now, when a developer sits down, he or she can get an up-to-the-minute summary of all the stuff that has happened to the code base since the last time he or she looked. Because it's an RSS reader, it keeps track of what you've already read. This is a great way to keep up to date at a really detailed level for what is happening to the code base.
This hasn't eliminated the need to create daily summary pages, but these can be much more terse, and focus on outstanding questions across the ocean. The Wiki contains a living history of the project, told one check-in at a time. For those who say that agile projects don't keep documentation, the Wiki on our project is a living, breathing history of the project at a really detailed level.
Our SVN2WIKI tool is a good example of piecing together a bunch of old and common technologies (SVN, Instiki, RSS) to create a great time saver for developers while improving the toughest part of our project.
Wednesday, May 17, 2006
The Ajax Experience Recap
I just finished speaking at The First (but certainly not the last) Ajax Experience, in San Francisco. It was held in the beautiful St. Francis hotel in downtown San Francisco, and it had the who's who of the Ajax world there. Ben Galbraith and Dion Almaer, the creators and maintainers of the Ajaxian web site, along with Jay Zimmerman of No Fluff, Just Stuff fame, put on a first-class conference. It was an interesting conference in that Ajax doesn't exist in a vacuum: it must be hosted on top of some other technology. I told one of my friends that it was like a condiments conference: you can't really have Ajax without some medium to present it upon. In any case, it was interesting to see such a diverse crowd rub elbows and get along so well. At one of the expert panels, we had the Lead Program Manager on the IE7 team sitting next to the creator of JavaScript. On another panel, the evangelist for the Microsoft Atlas framework sat next to the creator of Dojo (and 2 seats down from me). I represented pretty much the entire testing track there, showing a packed room how to use Selenium to test Ajax applications.
Because Ajax is at once broad (represented by the number of frameworks) but diverse (because it can be applied to just about any underlying web technology), I wondered if this conference would be a success. I can safely say that it was a resounding success, and it's going to happen again in the fall on the East coast. Kudos to Ben, Dion, and Jay for a great experience.
Because Ajax is at once broad (represented by the number of frameworks) but diverse (because it can be applied to just about any underlying web technology), I wondered if this conference would be a success. I can safely say that it was a resounding success, and it's going to happen again in the fall on the East coast. Kudos to Ben, Dion, and Jay for a great experience.
Buy 2, In Case You Lose the First
 The No Fluff, Just Stuff anthology (edited by yours truly) is now orderable (they have gone to the printer, meaning that you can pre-order them from Pragmatic Press or get the PDF version right now). Check out the book page on the Prag's site to see it, order it, and fetishize it. I suggest that you buy at least 2, in case you lose one. And, nothing say lovin' to your spouse like an anthology of technical articles. Great wedding gifts, too.
The No Fluff, Just Stuff anthology (edited by yours truly) is now orderable (they have gone to the printer, meaning that you can pre-order them from Pragmatic Press or get the PDF version right now). Check out the book page on the Prag's site to see it, order it, and fetishize it. I suggest that you buy at least 2, in case you lose one. And, nothing say lovin' to your spouse like an anthology of technical articles. Great wedding gifts, too.
Tuesday, May 09, 2006
Spreading the DSL Virus
Everywhere I go now (in a technical context anyway), I'm associated with the idea of Domain Specific Languages. At the No Fluff, Just Stuff expert panel this last weekend in Denver, my friend Scott Davis introduced me (we each introduced the member of the panel sitting on our right), and mostly what he said about me can be paraphrased as "he's the Typhoid Mary of DSL's". When I mentioned DSL's in answering a "Why is Ruby cool?" question, Ted Neward (the moderator) jokingly told me to not talk about it anymore.
But it's spreading further afield. I was at the Microsoft Technology Summit last week, and asked a DSL related question of Don Box when he was giving an Indigo talk. Afterwards, I chatted with him for a while about DSL's. Apparently, I got his attention. This week, he posted a blog entry looking for me to explain what the hell it was that I was talking about at MTS06. His blog entry and my reply is here. I pointed him to a great blog entry from my co-worker Jay Fields to illustrate to Don the power of this technique (found here).
As my regular reader(s) may know, I'm currently working on a book on DSLs for Pragmatic Press. The author team of Joe O'Brien, Jeremy Stell-Smith, Zak Tamsen, and myself are working hard to spread this virus far and wide.
But it's spreading further afield. I was at the Microsoft Technology Summit last week, and asked a DSL related question of Don Box when he was giving an Indigo talk. Afterwards, I chatted with him for a while about DSL's. Apparently, I got his attention. This week, he posted a blog entry looking for me to explain what the hell it was that I was talking about at MTS06. His blog entry and my reply is here. I pointed him to a great blog entry from my co-worker Jay Fields to illustrate to Don the power of this technique (found here).
As my regular reader(s) may know, I'm currently working on a book on DSLs for Pragmatic Press. The author team of Joe O'Brien, Jeremy Stell-Smith, Zak Tamsen, and myself are working hard to spread this virus far and wide.
Monday, April 24, 2006
Eating Sacred Hamburger
Software development cults tend to create sacred cows: habits and idioms that might have meant something at one time but only remain as baggage now. I tend to like to kill sacred cows and grill them up, with some nice lettuce, tomato, and a sesame seed bun. On my current project, we're actively killing some sacred cows.
Here are a couple of examples. Thankfully, Hungarian Notation has mostly been banished, except for one lingering, annoying location in the .NET world: the stupid "I" preface on interfaces. In fact, if you understand how interfaces should be used, this is exactly the opposite of what you want. In our application, every important semantic type is represented by an interface. Using interfaces like this makes it easier to do a whole host of things, including mocking out complex dependencies for testing. Why would you destroy the most important names in your application with Hungarian Notation telling you it's an interface? Ironically enough, that your semantic type is an interface is an implementation detail -- exactly the kind of detail you want to keep out of interfaces. I suspect this nasty habit developed in the .NET world because interfaces first came to the Microsoft world as COM (or, back when it started, OLE). It's a stupid cow now, and should be slaughtered.
Another sacred cow we're gleefully grilling up is the rule that all method names must use camel case. We're using this standard convention in our code, but have started using underscores for our test method names. Test methods tend to be long and descriptive, and it's hard to read long camel case names. Consider this test name:
Which of these is easier to read? The standard in .NET says that you use camel case, which we do...except in situations where it actually hampers productivity. If a cow gets in my way and slows me down, it's a goner.
In the book Pragmatic Programmer, Dave Thomas and Andy Hunt admonish developers to learn a new programing language every year. Seeing new ways of doing common tasks and learning new idioms is the best defense against sacred cows. Learning new languages helps you focus on how and why things work the way they do, divorced from syntax.
Here are a couple of examples. Thankfully, Hungarian Notation has mostly been banished, except for one lingering, annoying location in the .NET world: the stupid "I" preface on interfaces. In fact, if you understand how interfaces should be used, this is exactly the opposite of what you want. In our application, every important semantic type is represented by an interface. Using interfaces like this makes it easier to do a whole host of things, including mocking out complex dependencies for testing. Why would you destroy the most important names in your application with Hungarian Notation telling you it's an interface? Ironically enough, that your semantic type is an interface is an implementation detail -- exactly the kind of detail you want to keep out of interfaces. I suspect this nasty habit developed in the .NET world because interfaces first came to the Microsoft world as COM (or, back when it started, OLE). It's a stupid cow now, and should be slaughtered.
Another sacred cow we're gleefully grilling up is the rule that all method names must use camel case. We're using this standard convention in our code, but have started using underscores for our test method names. Test methods tend to be long and descriptive, and it's hard to read long camel case names. Consider this test name:
vs. this version:
[Test]
public void VerifyEndToEndSecurityConnectivityToInfrastructure()
[Test]
public void Verify_end_to_end_security_connectivity_to_infrastructure()
Which of these is easier to read? The standard in .NET says that you use camel case, which we do...except in situations where it actually hampers productivity. If a cow gets in my way and slows me down, it's a goner.
In the book Pragmatic Programmer, Dave Thomas and Andy Hunt admonish developers to learn a new programing language every year. Seeing new ways of doing common tasks and learning new idioms is the best defense against sacred cows. Learning new languages helps you focus on how and why things work the way they do, divorced from syntax.
Wednesday, April 19, 2006
Coming Soon...The Ajax Experience
Jay, the creator of No Fluff, Just Stuff, has started conducting single-topic, destination conferences. The first was last year, The Spring Experience, where he brought together the entire Spring universe in Florida for 3 days.
This year, he's doing it again with The Ajax Experience. This amazing show takes place in San Franciso, May 10 - 12th (the week before JavaOne). It features the entire Who's Who of Ajax luminaries (and some dim lights, like me). I'm going to talk about testing Ajax applications using Selenium. And that's no coincidence. Jay has tried to get the creators of each of the parts of the Ajax world together, and I'm talking about Selenium because it was created by ThoughtWorks. Check out the web site and come to San Francisco. It should be an amazing 3 days.
This year, he's doing it again with The Ajax Experience. This amazing show takes place in San Franciso, May 10 - 12th (the week before JavaOne). It features the entire Who's Who of Ajax luminaries (and some dim lights, like me). I'm going to talk about testing Ajax applications using Selenium. And that's no coincidence. Jay has tried to get the creators of each of the parts of the Ajax world together, and I'm talking about Selenium because it was created by ThoughtWorks. Check out the web site and come to San Francisco. It should be an amazing 3 days.
Sunday, March 26, 2006
Walking on the Wrong Side of the Street
The first time I ever went to Sydney, Australia, I couldn't get in sidewalk sync. It seemed like every time I walked down the sidewalk, I was walking head-long into groups of people. It was almost like I was swimming upstream. Then it dawned on me: these folks are used to driving on the left-hand side of the road, so they tend to walk on the left-hand side of the sidewalk too. Suddenly, it made sense, and my sidewalking skills improved overnight.
The same thing occurred to me this morning while I was walking from my hotel to the offices in ThoughtWorks India, and I noticed that everyone here (also being a former British colony) walks and drives on the left-hand side. Which side you tend towards when walking is one of those intrinsic, automatic things that you don't even realize is part of your cultural literacy until you go somewhere where it's the opposite.
The same kind of automatic response happens when developing software. I span the Java and .NET worlds, and I think it's interesting to see the kinds of cultural ticks that programmers from specific platforms develop. For example, in the Java world, you build frameworks for everything. In the .NET world, you organize things around the limitations of namespaces and solution files in Visual Studio, because it's the only real choice when it comes to IDEs. I have an advantage because I live part time in both worlds, so I try to spot cultural eccentricities whenever I sense myself walking on the wrong side of the street. Some things make sense in both cultures (like unit testing), while others are little more than arbitrary cultural baggage.
The same thing occurred to me this morning while I was walking from my hotel to the offices in ThoughtWorks India, and I noticed that everyone here (also being a former British colony) walks and drives on the left-hand side. Which side you tend towards when walking is one of those intrinsic, automatic things that you don't even realize is part of your cultural literacy until you go somewhere where it's the opposite.
The same kind of automatic response happens when developing software. I span the Java and .NET worlds, and I think it's interesting to see the kinds of cultural ticks that programmers from specific platforms develop. For example, in the Java world, you build frameworks for everything. In the .NET world, you organize things around the limitations of namespaces and solution files in Visual Studio, because it's the only real choice when it comes to IDEs. I have an advantage because I live part time in both worlds, so I try to spot cultural eccentricities whenever I sense myself walking on the wrong side of the street. Some things make sense in both cultures (like unit testing), while others are little more than arbitrary cultural baggage.
Friday, March 24, 2006
Dynamic Typing in the Strangest Places
One of my favorite things in college was the accidental synergy that happened between the collection of classes taken in a single quarter. Sure, compiler theory and automata match one another, but it's even more interesting when a history and computer science class find ways to complement one another. I get some of the same type of cross-pollination of ideas when speaking at conferences -- some of the topics end up complementing each other in odd ways.
It happened recently in St. Louis at No Fluff, Just Stuff. Part of the weekend, I was talking about how document centric messaging in SOA avoids endpoint versioning headaches. Later in the weekend, I was talking about the flexibility afforded by dynamic languages and their loose typing. Then, it occurred to me: SOA and the document centric approach is really just another version of dynamic or loose typing. If you free the plumbing from having to know what types you are passing (in this case, just a blob of XML), you create a more flexible system, able to withstand changes more gracefully. Just like with dynamic languages.
I've been sauteing in this idea for a while: we are building the same kind of application right now on the project I'm on. And, even though it's written in .NET 2, we take advantage of loose typing in the transport layer, which ultimately makes for a more robust application. How do we handle catching version conflicts? The way you should handle all such situations: unit testing. Loose typing + unit testing provides the same security you get with strongly typed languages but much more flexibility
It happened recently in St. Louis at No Fluff, Just Stuff. Part of the weekend, I was talking about how document centric messaging in SOA avoids endpoint versioning headaches. Later in the weekend, I was talking about the flexibility afforded by dynamic languages and their loose typing. Then, it occurred to me: SOA and the document centric approach is really just another version of dynamic or loose typing. If you free the plumbing from having to know what types you are passing (in this case, just a blob of XML), you create a more flexible system, able to withstand changes more gracefully. Just like with dynamic languages.
I've been sauteing in this idea for a while: we are building the same kind of application right now on the project I'm on. And, even though it's written in .NET 2, we take advantage of loose typing in the transport layer, which ultimately makes for a more robust application. How do we handle catching version conflicts? The way you should handle all such situations: unit testing. Loose typing + unit testing provides the same security you get with strongly typed languages but much more flexibility
Tuesday, March 07, 2006
Finally, An Accurate Representation of My Graphical Skills
During a lunchtime conversation today, because of the specific context, I came up with a great quote about my abilities as a graphical designer:
Graphical design is like pornography: I know it when I see it, I don't want to participate in it, and you don't want to see me try it either.
'Nuff said.
Graphical design is like pornography: I know it when I see it, I don't want to participate in it, and you don't want to see me try it either.
'Nuff said.
A Dearth of Fluff, Significant Stuff
As my regular reader(s?) must have noticed, I've been very quiet for a while. No, I haven't given up pontificating; I've been working diligently on a new year of No Fluff, Just Stuff presentations. Every year, I cull some of my old talks from the herd and send them to the virtual glue factory and add some new, spry colts to the fold. This year, I've added about 4 new talks and killed the same number, and I've been spending the last couple of months getting them in shape. This last weekend was the debut of a couple of them (along with 5 of my existing talks).
No Fluff, Just Stuff Gateway Software Symposium occurred in St. Louis over the weekend. I gave a total of 7 talks: clean Up Your Code, Advanced Enterprise Debugging Techniques, SOA & ESB: The Future of Distributed Computing or the Return of the Son of CORBA?, Pragmatic XP, the new Testing with Selenium, the also new The Productive Programmer, and finally Language-oriented Programming and Language Workbenches. Whew! It was a long weekend, but the new talks turned out well (only requiring minor tweaks, not major overhauls). And, someone was nice enough to blog about one of my talks (always good to get feedback).
It's great to get back to No Fluff. Many of the speakers are good friends, so it's good to see them again. One of the speakers made an excellent observation that also applies to me: I have more friends that travel the country every weekend than I do at home! It's good to be back in the saddle again.
No Fluff, Just Stuff Gateway Software Symposium occurred in St. Louis over the weekend. I gave a total of 7 talks: clean Up Your Code, Advanced Enterprise Debugging Techniques, SOA & ESB: The Future of Distributed Computing or the Return of the Son of CORBA?, Pragmatic XP, the new Testing with Selenium, the also new The Productive Programmer, and finally Language-oriented Programming and Language Workbenches. Whew! It was a long weekend, but the new talks turned out well (only requiring minor tweaks, not major overhauls). And, someone was nice enough to blog about one of my talks (always good to get feedback).
It's great to get back to No Fluff. Many of the speakers are good friends, so it's good to see them again. One of the speakers made an excellent observation that also applies to me: I have more friends that travel the country every weekend than I do at home! It's good to be back in the saddle again.
Monday, February 20, 2006
Dependency Injection in Geronimo, Part 2
As surely as Spring follows winter, the 2nd part of my depenency injection article on DeveloperWorks is now live. This version builds on the "raw" topic of dependency injection in the 1st part and shows how it applies to Geronimo. Geronimo has a very interesting architecture, and will surprise some people who think that "dependency injection" == "Spring".
Saturday, February 11, 2006
My Last Borland Post Ever (I Promise!)
Those of you who follow my blog know that I post an inordinate amount of material about Borland. I have a long-standing love for Borland: my first book was on Delphi (Developing with Delphi: Object-oriented Techniques) and my second was on JBuilder (JBuilder 3 Unleashed). I learned about real software development using Borland tools. When I bought my first computer, I bought just 2 pieces of software: DOS 3.3 and Turbo Pascal 5. And I didn't need any other software for almost a year.
Borland has perpetual financial and directional problems over the years. But, like loyal fans of Saturday Night Live, most of us stuck around even when it sucked (Inprise, anyone?)
Now, though, Borland has taken the last fatal step towards irrelevance: they are in the process of divesting their entire IDE division (check out this eWeek article). Yes, that's right: the company that brought us Turbo Pascal, Turbo C, Turbo Prolog (OK, maybe we didn't need that one), Delphi, and JBuilder will no longer sell a single compiler. I wonder what Anders thinks about this (or if he even noticed).
Borland is reinventing itself as a strictly ALM (Application Lifecycle Management) company, selling tools that have awesome support for Big Design Up Front (BDUF) like CaliberRM, TogetherJ, and the Segue tools they just acquired. What a great day for Waterfall projects (I wonder if they would consider sponsoring the Waterfall 2006 conference)?
For those of us with an irrational (pun intended) love of Borland, this is indeed a dark day. RIP.
Borland has perpetual financial and directional problems over the years. But, like loyal fans of Saturday Night Live, most of us stuck around even when it sucked (Inprise, anyone?)
Now, though, Borland has taken the last fatal step towards irrelevance: they are in the process of divesting their entire IDE division (check out this eWeek article). Yes, that's right: the company that brought us Turbo Pascal, Turbo C, Turbo Prolog (OK, maybe we didn't need that one), Delphi, and JBuilder will no longer sell a single compiler. I wonder what Anders thinks about this (or if he even noticed).
Borland is reinventing itself as a strictly ALM (Application Lifecycle Management) company, selling tools that have awesome support for Big Design Up Front (BDUF) like CaliberRM, TogetherJ, and the Segue tools they just acquired. What a great day for Waterfall projects (I wonder if they would consider sponsoring the Waterfall 2006 conference)?
For those of us with an irrational (pun intended) love of Borland, this is indeed a dark day. RIP.
Continuous Integration Conference
An interesting (free!) conference is coming to Chicago in early April this year, an Open Space event on Continuous Integration and Automated Testing. Both of these subjects are dear to my heart, so I'm hoping to help get the word out about this conference. They organizers haven't set the date yet because they need to see how many people are interested before they will know how big a space to reserve.
Support CI and AT: contact Jeffrey Fredrick (jtf@agitar.com) or Paul Julius (pj@thoughtworks.com) through the Yahoo group groups.yahoo.com/group/citcon and sign up for the mailing list.
Automation and Testing are Good Things!
Support CI and AT: contact Jeffrey Fredrick (jtf@agitar.com) or Paul Julius (pj@thoughtworks.com) through the Yahoo group groups.yahoo.com/group/citcon and sign up for the mailing list.
Automation and Testing are Good Things!
Wednesday, February 08, 2006
Dependency Injection in Geronimo Part 1
IBM DeveloperWorks has posted the first of a two-part series on dependency injection in the Geronimo J2EE container. This article focuses on the mechanisms of DI and uses PicoContainer as the container. I did this to divorce the idea of DI from the particular implementation in Geronimo. One of the problems I see in concepts like DI revolves around how you learn it: the implementation from which you learn influences your perception of if forever. Many developers think that DI and the way Spring works are the same thing. By using the lightest weight container I could find (PicoContainer), I hope to show DI in as context-free an environment as possible. The next part of the article takes the concepts and injects (pun intended) them in to Geronimo.
Tuesday, February 07, 2006
SOA Under a Giant Arch
I'm flying to St. Louis tonight to speak at the Gateway JUG. I'm doing my SOA: The Future of Distributed Computing or the Return of the Son of CORBA? talk, helping to promote the upcoming No Fluff, Just Stuff Gateway Software Symposium. Because there is so much sound and fury with so little substance in most SOA discussions, I'm trying to take a pragmatic approach to building SOA, which includes the (what I consider essential) focus on agile development techniques. I feel like I can offer some insight on this subject because I've lived through a lot of distributed computing initiatives and seen a lot of failures. This talk is about how to achieve some of the lofty goals espoused by SOA advocates with a healthy dose of skepticism.
Thursday, February 02, 2006
D-Cubed
I recently read about a most interesting innovation in software development methodology I've heard in a while: Defect Driven Design (D3, pronounced "D Cubed"). This methodology addresses the weak points of most other development methodologies.
Working in D3 is very simple. At the start of the project, you announce that all development is complete and the application is ready for user acceptance testing. The first thing the user will say is "Hey, I thought there was supposed to be an icon on the desktop to launch the application". That's our first defect. We implement code to put an icon on the desktop and announce again that we are done. The user clicks on the icon and nothing happens: "Where is the application?" That's our next defect. You can imagine what the rest of the development rhythm.
The brilliance in this methodology lies in the estimation power. We can estimate with absolute accuracy: 0 days. The entire lifecycle lies in maintenance, which is more realistic because useful software is never actually complete.
Working in D3 is very simple. At the start of the project, you announce that all development is complete and the application is ready for user acceptance testing. The first thing the user will say is "Hey, I thought there was supposed to be an icon on the desktop to launch the application". That's our first defect. We implement code to put an icon on the desktop and announce again that we are done. The user clicks on the icon and nothing happens: "Where is the application?" That's our next defect. You can imagine what the rest of the development rhythm.
The brilliance in this methodology lies in the estimation power. We can estimate with absolute accuracy: 0 days. The entire lifecycle lies in maintenance, which is more realistic because useful software is never actually complete.
Monday, January 30, 2006
Conference in a Castle
It's already time for the first conference of the year. I think this is the earliest start I've ever had. I'm speaking this weekend at the Javagruppen Arskonference conference, conducted in the Hindsgavl castle in Denmark. I heard about this conference from colleagues last year -- they had a blast, so I'm looking forward to it. I'm doing 2 talks, both on Domain Specific Languages (Theory and Practice). This will be my first trip to Denmark so, given my love of traveling to new places, should prove to be a fun trip.
Sunday, January 15, 2006
Can I Get Some Rails at this Boutique?
At the Newark No Fluff, Just Stuff show last year, someone from Java Boutique interviewed speakers during the course of the symposium. It was the end of the day and he was still missing some of the speakers, so he decided he would just interview us together. The hot topic of the conference was Ruby on Rails. Thus, myself and two of the people I respect most, Stuart Halloway and Justin Gehtland (from Relevance), talked for about 20 minutes about Ruby, Rails, and Java. The interview is just now out at the Java Boutique web site. It's sometimes interesting what you say when you are tired, hungry, and sitting next to 2 brilliant people. Upon reflection, I like the bit about the bicycle (which I made up on the spot and forgot until I re-read this interview).
Monday, January 09, 2006
Pervasive Search
One of my good friends has a great expression when he sees some really cool technology goodie that we'll get "Real Soon Now": "I want to live there!".
One of the touted features of the next version of Windows is pervasive search, or search at the operating system level. I was skeptical of the value of this feature. After all, we now have Google Desktop, right? I can search and find documents pretty quickly now.
However, what's missing from Google Desktop is the "pervasive" part. I didn't fully appreciate this missing element until I started using the Mac, because Mac OS X now has Spotlight, Apple's version of pervasive search. Spotlight has a little icon on the menubar to let you search for stuff, just like Google search. But the pervasive part is more useful to me. Check out the standard Mac save dialog:

Because search is embedded at the OS level, I can use search to save files instead of navigating my document hierarchy. When I save a file on the Mac now, I search for the folder in which I know it belongs, then I name the file. It's not like I fear or don't understand hierarchies in a file system. But why bother doing all that navigation? I know where I want to put it, and the OS should be smart enough to let me tell it without all the ceremony. That's pervasive search, and it has changed the way I use my computer. Now, I can't wait until my work OS catches up to what is one of my favorite features of my favorite OS.
Not that Spotlight is perfect yet. It's annoyingly slow, and it sometimes yields some false positives. That irritates me. But, the benefit outweighs the annoyance factor by a lot. And I doubt that the first version of pervasive search in Windows will work perfectly either. I view this as a "I want to live there" feature: I can't wait until I can stop navigating hierarchies most of the time.
One of the touted features of the next version of Windows is pervasive search, or search at the operating system level. I was skeptical of the value of this feature. After all, we now have Google Desktop, right? I can search and find documents pretty quickly now.
However, what's missing from Google Desktop is the "pervasive" part. I didn't fully appreciate this missing element until I started using the Mac, because Mac OS X now has Spotlight, Apple's version of pervasive search. Spotlight has a little icon on the menubar to let you search for stuff, just like Google search. But the pervasive part is more useful to me. Check out the standard Mac save dialog:
Because search is embedded at the OS level, I can use search to save files instead of navigating my document hierarchy. When I save a file on the Mac now, I search for the folder in which I know it belongs, then I name the file. It's not like I fear or don't understand hierarchies in a file system. But why bother doing all that navigation? I know where I want to put it, and the OS should be smart enough to let me tell it without all the ceremony. That's pervasive search, and it has changed the way I use my computer. Now, I can't wait until my work OS catches up to what is one of my favorite features of my favorite OS.
Not that Spotlight is perfect yet. It's annoyingly slow, and it sometimes yields some false positives. That irritates me. But, the benefit outweighs the annoyance factor by a lot. And I doubt that the first version of pervasive search in Windows will work perfectly either. I view this as a "I want to live there" feature: I can't wait until I can stop navigating hierarchies most of the time.
Subscribe to:
Posts (Atom)

